Eins Vorweg Port Knocking ist kein 100% Schutz für den ssh Dienst , eine saubere Konfiguration ist notwendig. Was man aber damit erreicht ist das Portscanner diesen Port als nicht offen sehen. Somit hat man schon mal einen Teil der Angriffe weggefiltert. Hat der Angreifer jedoch die Möglichkeit den Traffic zwischen Client und Server mitzuschneiden kommt er früher oder später auf die Sequenz und kann den Port öffnen.
Verwendet hier keine fortlaufende Ports und mischt am besten die Protokolle.Wenn ein Portscan auf den Server ausgeführt wird ist sonst die Gefahr zu groß das durch Zufall die Sequenz getroffen wird.
Ich habe das einfach mal aus Interesse eingerichtet und getestet, und es funktioniert
 Installation von knockd (Server und Client)
Installation von knockd (Server und Client)
apt install knockd
Installation von iptables (Server)apt install iptables iptables-persistent
Konfiguration des knockd (Server)
Die Konfiguration des knock Daemon (knockd) wird in der Datei
/etc/knockd.conf und
/etc/default/knockd durchgeführt.
In der Datei
/etc/default/knockd ändern wir die Startart und definieren die KNOCKD_OPTS.
...
START_KNOCKD=1
KNOCKD_OPTS="-i enp0s3"
enp0s3 ist hier der Networkinterface Name.
START_KNOCKD=1 sorgt dafür das der Daemon beim Systemstart mit gestartet wird.
Jetzt kümmern wir uns um die Datei
/etc/knockd.conf und schließen die Konfiguration ab.
[options]
logfile = /var/log/knockd.log
[openSSH]
sequence = 8000,7000,9000,2123:udp
seq_timeout = 5
command = /usr/sbin/iptables -I INPUT -s %IP% -p tcp --dport 22 -j ACCEPT
tcpflags = syn
[closeSSH]
sequence = 9000,7000,8000,2123:udp
seq_timeout = 5
command = /usr/sbin/iptables -D INPUT -s %IP% -p tcp --dport 22 -j ACCEPT
tcpflags = synAlle Konfigurationsmöglichkeiten kann man sich mit man knockd anschauen (und es gibt viele). Für das Beispiel hier verwende ich eine rudimentäre Konfiguration. Die Ports die unter Sequenz (sequence) angegeben sind muss man nacheinander "anklopfen" dann wird das command ausgeführt. Hier sieht man das iptables den Client auf den SSH Port freigibt. Und eben wieder entfernt wenn die Sequenz für closeSSH übergeben wird.
Nachdem die Konfiguration abgeschlossen ist muss der Dienst aktiviert und gestartet werden.
systemctl enable knockd && systemctl start knockd
Jetzt bereiten wir die Firewall für den Einsatz vor. Hiermit erstellen wir eine Regel das vorhandene Verbindungen nicht getrennt werden
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
in der folgenden Regel verbieten wir die Connection auf den Port 22
iptables -A INPUT -p tcp --destination-port 22 -j DROP
jetzt wird das ganze noch gespeichert das es einen reboot überlebt
iptables-save > /etc/iptables/rules.v4
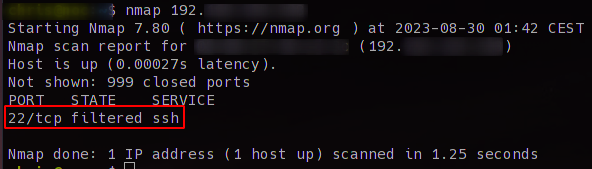
Wenn ihr euch jetzt den Server einmal mit nmap anschaut, natürlich von einem anderen Client, ist der Port geschlossen.
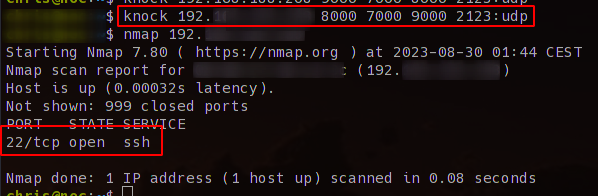
Ruft man jetzt knock auf dem Client mit der richtigen Sequenz auf wird der Port geöffnet
knock SERVERIP 8000 7000 9000 2123:udp
das kann man auch wieder schön mit nmap ermitteln.
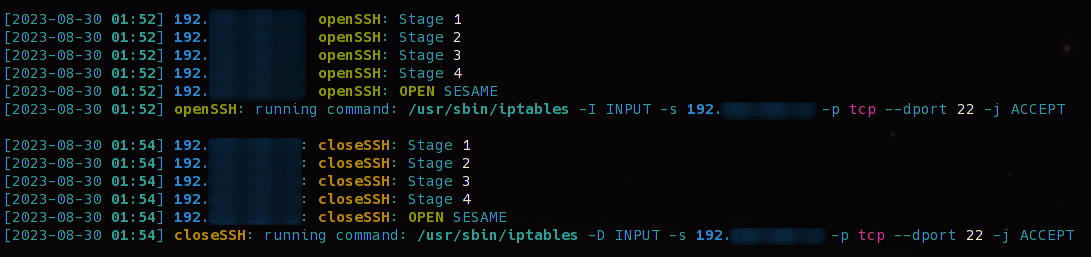
Im Logfile von knockd sieht das ganze dann so aus. Im ersten Block wurde die Sequenz richtig angegeben und somit der Client zugelassen. Im zweiten Block wurde die Sequenz richtig angegeben und der Port wurde wieder geschlossen.